
Data quality dimensions – 10 metrics you should be measuring – Data Ladder
“As organizations accelerate their digital business efforts, poor data quality is a major contributor to a crisis in information trust and business value, negatively impacting financial performance.”
Ted Friedman, VP Analyst, Gartner
Mục lục
Data quality – Can you use the data you have?
ISO/IEC 25012 standard defines data quality as:
The degree to which data satisfies the requirements of its intended purpose.
If the stored data is unable to fulfill the requirements of its organization, then it is said to be of poor quality and it is deemed useless. All the time and effort an organization invests in capturing, storing, managing their data assets will be wasted if the data is not kept clean and error-free. Here, a list of data quality KPIs or data quality measures can be very useful to assess the current quality state of your data.
In this blog, we will learn how do you measure data quality and look at different dimensions of data quality with examples. Let’s get started.
How to measure data quality?
The definition of data quality implies that it means something different for every business – depending on how they wish to use the data. For example, for some businesses, data accuracy is more important than data completeness, while for others, the opposite may be true. This concept introduces the idea that data quality can be measured in different ways.
What is a data quality dimension?
A metric that quantitatively measures data quality.
How many data quality dimensions are there?
You will often find people say that there are six dimensions of data quality, while others say there are eight data quality dimensions. Since data can be measured in different ways, the number and types of data quality measures can vary depending on how you want to use your data.
Data quality dimensions correspond to data hierarchy
Data hierarchy in any organization starts with a single data value. Data values of various attributes are grouped together for a specific entity or occurrence to form a data record. Multiple data records (representing multiple occurrences of same type) are grouped together to form dataset. These datasets can reside at any source or application to satisfy the needs of an organization.
Data quality dimensions behave and are measured differently at each level of data hierarchy. Technically speaking, all data quality metrics fall under two broad categories: the first one relates to the data’s intrinsic characteristics, while the second relates to its contextual characteristics. See the following image to understand how data quality is assessed at each level.
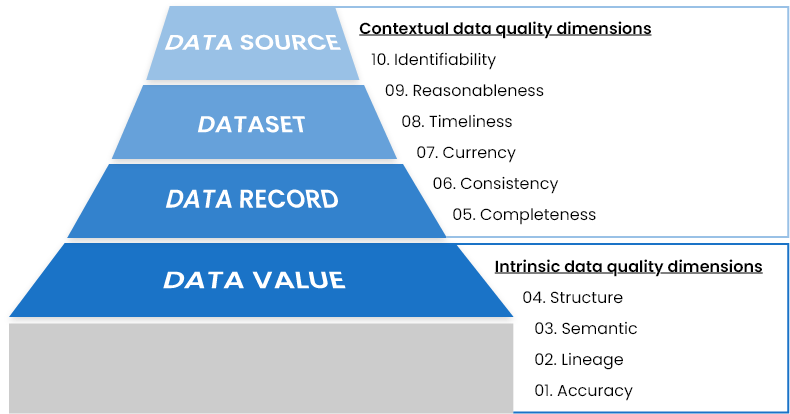
Top 10 data quality metrics you should measure
In this article, I have covered a list of ten data quality metrics that play a critical role in attaining a complete quality profile of your data. Let’s take a look at both these categories and the data quality dimensions they contain.
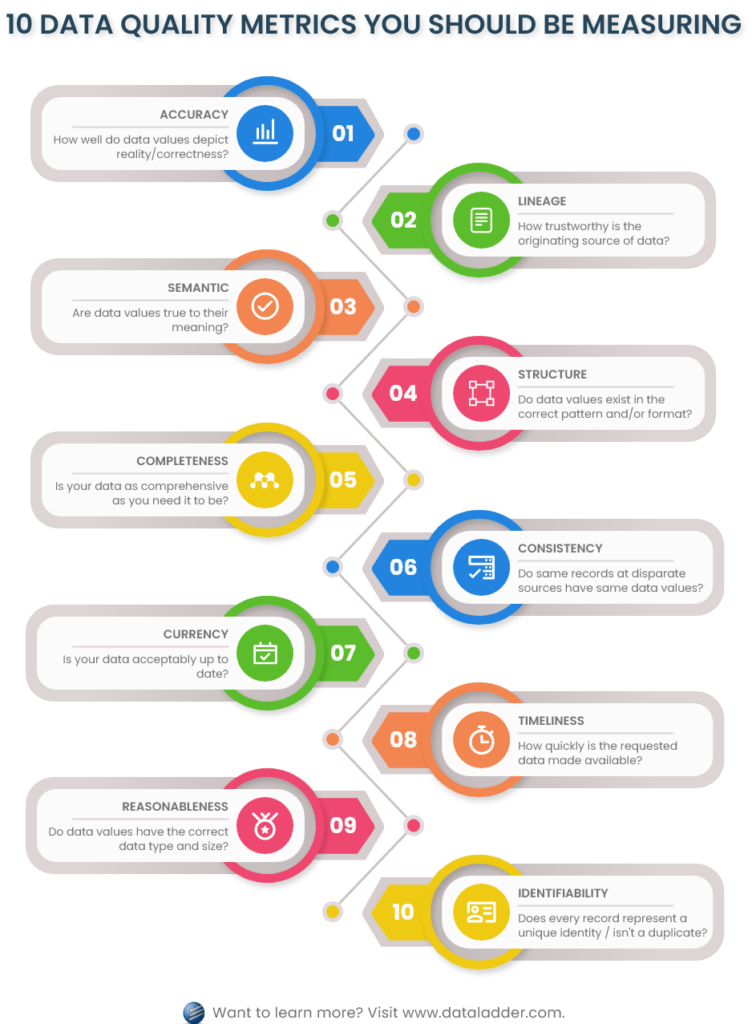
A. Intrinsic data quality dimensions
These dimensions directly assess and evaluate the data value – at the granular level; its meaning, availability, domain, structure, format, and metadata, etc. These dimensions do not consider the context in which the value was stored, such as its relationship with other attributes or the dataset it resides in.
Following four data quality dimensions fall under intrinsic category:
1. Accuracy
HOW WELL DO DATA VALUES DEPICT REALITY/CORRECTNESS?
Accuracy of data values is measured by verifying them against a known source of correct information. This measurement could be complex if there are multiple sources that contain the correct information. In such cases, you need to select the one that is the most inclusive to your domain, and compute the degree of agreeability of each data value against the source.
Data quality metrics examples: Accurate data values
Consider an employee database that contains the contact number of employees as an attribute. An accurate phone number is the one that is correct and exists in reality. You can verify all phone numbers in your employee database by running them against an official database containing list of valid phone numbers.
2. Lineage
HOW TRUSTWORTHY IS THE ORIGINATING SOURCE OF DATA VALUES?
The lineage of data values is verified or tested by validating the originating source, and/or all sources that have updated the information over time. This is an important measure as it proves the trustworthiness of the data captured, and as it evolves over time.
Data quality metrics examples: Lineage of data
In the above example, employee contact numbers are trustworthy if they are coming from a valid source. And the most valid source for this type of information is the employee himself – either the data is inputted the first time or updated over time. Alternatively, if contact numbers were inferred from a public phone directory, this originating source is definitely questionable and could potentially contain errors.
3. Semantic
ARE DATA VALUES TRUE TO THEIR MEANING?
To ensure data quality, the data value must be semantically correct; which relates to its meaning – especially in context of the organization or department it is used. Information is usually exchanged between different departments and processes in an enterprise. In such cases, stakeholders and users of data must agree to the meaning of all attributes involved in the dataset, so that they can be semantically verified.
Data quality metrics examples: Semantically correct data values
Your employee database can have two attributes that store employee contact numbers, namely Phone Number 1 and Phone Number 2. An agreed definition of both attributes could be that Phone Number 1 is employee’s personal cell number, while Phone Number 2 is his residential telephone number.
It is important to note that the accuracy measure will validate the existence and realness of both these numbers, but the semantic measure will ensure that both these numbers are true to their implicit definition – meaning, the first one is a cell number, while the second one is a residential telephone number.
4. Structure
DO DATA VALUES EXIST IN THE CORRECT PATTERN AND/OR FORMAT?
Structural analysis relates to verifying the representation of data values – meaning, the values have valid pattern and format. These checks are better made and enforced at data entry and capture, so that all incoming data is first validated and if needed, transformed as required, before storing in the application.
Data quality metrics examples: Structurally correct data values
In the above example of employee database, all values in the column of Phone Number 1 must be correctly structured and formatted. An example of poorly structured phone number is: 134556-7(9080. Although, it is possible that the number itself (exclusive of the additional hyphen and parenthesis) is accurate as well as semantically correct. But the correct format and pattern of the number should be:
+1-345-567-9080.
B. Contextual data quality dimensions
These dimensions assess and evaluate data in their entire context – such as, considering all data values of an attribute together, or data values grouped in records, and so on. These dimensions focus on the relationships between different data components, and their fitness to data quality expectations.
Following six data quality dimensions fall under contextual category:
5. Completeness
IS YOUR DATA AS COMPREHENSIVE AS YOU NEED IT TO BE?
Completeness defines the degree to which the needed data values are filled and are not left blank. This can be calculated vertically (attribute-level) or horizontally (record-level). Usually, fields are marked mandatory/required to ensure completeness of a dataset. While calculating completeness, its three different types must be considered to ensure accuracy of the results:
- Required field that cannot be left empty; for example, National ID of an employee.
- Optional field that does not necessarily need to be filled; for example, Hobbies field for an employee.
- Inapplicable field that becomes irrelevant based on the context of the record, and should be left blank; for example, Spouse’s Name for a non-married individual.
Data quality metrics examples: Complete data
An example of vertical completeness is calculating the percentage of employees for whom Phone Number 1 is provided. And the example of horizontal completeness is calculating the percentage of information that is complete for a particular employee; for instance, an employee’s data can be 80% complete, where his contact number and residential address is missing.
6. Consistency
DO DISPARATE DATA STORES HAVE THE SAME DATA VALUES FOR THE SAME RECORDS?
Consistency checks whether data values stored for the same record across disparate sources are free from contradiction, and are exactly the same – in terms of meaning as well as structure and format.
Consistent data helps to perform uniform and accurate reporting across all functions and operations of your enterprise. Consistency does not only relate to the meanings of data values, but also, their representation; for instance, when values are not applicable or are unavailable, consistent terms must be used to represent the unavailability of data across all sources.
Data quality metrics examples: Consistent data
Employee information is usually stored in HR management applications, but the database has to be shared or replicated for other departments as well, such as payroll or finances. To ensure consistency, all attributes stored across databases must have the same values. Otherwise, difference in Bank Account Number or other such critical fields can become a huge problem.
7. Currency
IS YOUR DATA ACCEPTABLY UP TO DATE?
Currency relates to the degree to which data attributes are of the right age in context of their use. This measure helps to keep the information up-to-date and in conformance with the current world, so that your snapshots of data are not weeks or months old, leading you to present and base critical decisions on outdated information.
To ensure currency of your dataset, you can set reminders to update data, or set limits to an attribute’s age, ensuring all values are subjected to review and update in a given time.
Data quality metrics examples: Current data
Your employee’s contact information should be reviewed timely to check if anything was recently changed, and needs to be updated in the system.
8. Timeliness
HOW QUICKLY IS THE REQUESTED DATA MADE AVAILABLE?
Timeliness measures the time it takes to access the requested information. If your queried data requests take too long to finish, it could be that your data is not well-organized, related, structured, or formatted.
Data quality timeliness also measures how quickly is the new information available for use across all sources. If your enterprise employs complex and time-consuming processes to store incoming data, users can end up querying and using old information at some points.
Data quality metrics examples: Timeliness
To ensure timeliness, you can check the response time of your employee database. Moreover, you can also test how long it takes for the information updated in the HR application to be replicated in the payroll application, and so on.
9. Reasonableness
DO DATA VALUES HAVE THE CORRECT DATA TYPE AND SIZE?
Reasonableness measures the degree to which data values have a reasonable or understandable data type and size. For instance, it is common to store numbers in an alphanumeric string field, but reasonability will make sure that if an attribute only stores numbers, then it should be of number type.
Moreover, reasonability also enforces maximum and minimum character limit on attributes so that there are no unusually long strings in the database. The reasonability measure reduces space for errors by enforcing constraints on an attribute’s data type and size.
Data quality metrics examples: Reasonableness
The Phone Number 1 field – if stored without the hyphens and special characters – should be set to numeric and have a max character limit so that extra alphanumeric characters are not mistakenly added.
10. Identifiability
DOES EVERY RECORD REPRESENT A UNIQUE IDENTITY AND IS NOT A DUPLICATE?
Identifiability calculates the degree to which data records are uniquely identifiable and are not duplicates of each other.
To ensure identifiability, a uniquely identifying attribute is stored in the database for each record. But in some cases, such as the case of healthcare organizations, personally identifiable information (PII) is removed to guard patient confidentiality. This is where you may need to perform fuzzy matching techniques to compare, match, and merge records.
Data quality metrics examples: Identifiability
An example of identifiability is to enforce that every new record in the employee database must contain a unique Employee ID Number through which they will be identified.
How to build a unified, 360 customer view
Download this whitepaper to learn why it’s important to consolidate your customer data and how you can get a 360 view of your customers.
Download
Which data quality dimensions to use?
We went through the top ten most commonly used data quality metrics. Since every enterprise has its own set of requirements and KPIs, you may need to use other metrics or create custom ones. The selection of data quality dimensions depends on multiple factors, such as the industry your business operates in, the nature of your data, and the role it plays in the success of your goals.
Since every industry has its own data rules, reporting mechanism, and measurement criteria, a different set of data quality metrics are adopted to satisfy the needs of each case, for example government agencies, finance and insurance departments, healthcare institutes, sales and marketing, retail, or educational systems, etc.
Automating data quality measurement using DataMatch Enterprise
Considering how complex data quality measurement can get, it is a process usually expected to be performed by tech- or data-savvy professionals. The unavailability of advanced profiling capabilities in a self-service data quality tool is a commonly faced challenge.
A self-service data quality tool that can output quick 360-view of data and identify basic anomalies, such as blank values, field data types, recurring patterns, and other descriptive statistics is a basic requirement for any data-driven initiative. Data Ladder’s DataMatch Enterprise is a fully powered data quality solution that does not only offer data quality assessment, but goes on to perform detailed data cleansing, matching, and merging.
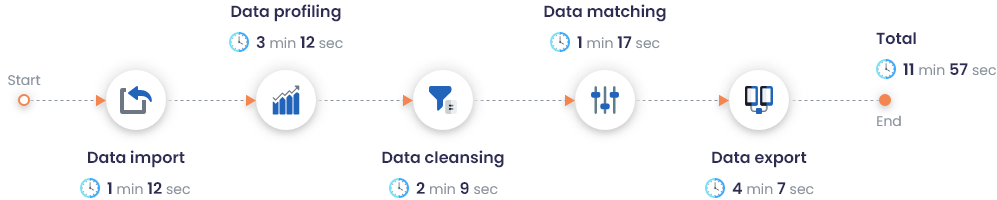
DME performance on a dataset of 2M records
With DataMatch Enterprise, you can perform quick accuracy, completeness, and validation checks. Instead of manually identifying and marking discrepancies present in your dataset; with DME, your team can single-handedly generate a report that labels and numbers various data quality metrics in just a few seconds – even with a sample size as big as 2 million records.
DataMatch Enterprise’s performance on a dataset containing 2M records was recorded as follows:
Detailed data quality profile generation and filtering
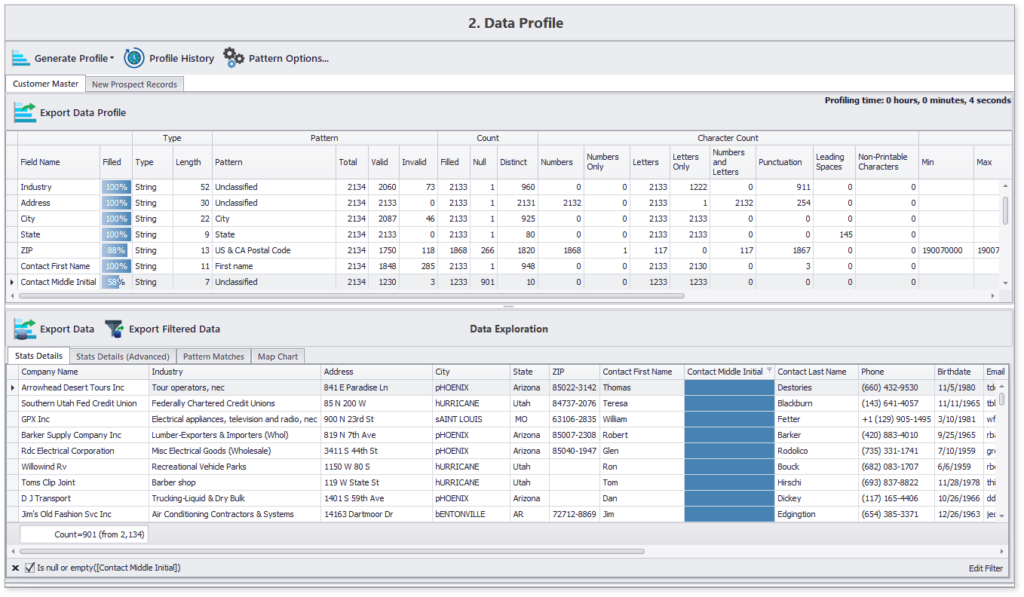
Here’s a sample profile generated using DME in less than 10 seconds for about 2000 records:
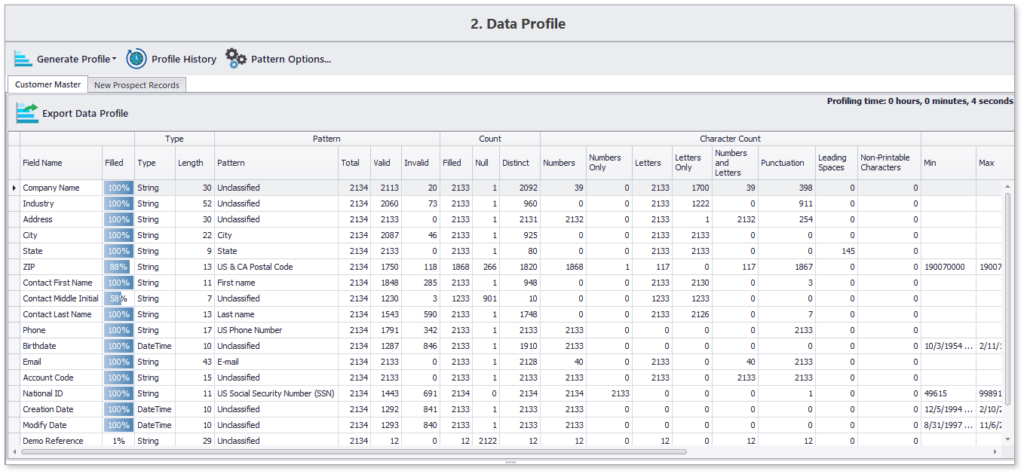
This concise data profile highlights content and structure details of all chosen data attributes. Moreover, you can also navigate to specifics, such as the list of those 12% records which are missing the contact’s middle name.
Getting Started with DataMatch Enterprise
Download this guide to find out the vast library of features that DME offers and how you can achieve optimal results and get the most out of your data with DataMatch Enterprise.
Download
To know more about how our solution can help solve your data quality problems, sign up for a free trial today or set up a demo with one of our experts.





