
Designing a Framework for Data Quality Management – Data Ladder
According to O’Reilly’s report on The state of data quality 2020, 56% of organizations face at least four different types of data quality issues, while 71% face at least three different types. It is not surprising that the number and type of data quality issues faced varies between different organizations. But it is surprising that most companies tend to adopt and implement generalized fixes to solve their data quality problems – instead of designing something that serves their unique case.
This is where an end-to-end data quality framework comes in. In a previous blog, we discussed the top data quality processes to know before designing a data quality framework. In this blog, we will see how these processes can be utilized to design a continuous data quality improvement plan.
Let’s dive in.
Mục lục
What is a data quality framework?
Data quality framework (also known as data quality lifecycle) is a systematic process that monitors the current state of data quality and ensures that it is maintained above defined thresholds. It is usually designed in a cycle so that the results are continuously assessed and errors are corrected systematically in time.
Example of a data quality framework
Businesses looking to fix their data quality problems adopt almost the same data quality processes. But a data quality framework is where their plans differ. For example, a data quality management system will definitely use some basic data standardization techniques to achieve a consistent view across all data values. But the exact nature of these standardization techniques depends on the current state of your data and what you wish to achieve.
This is why, here we will look at a generic yet comprehensive data quality framework – something that any organization can adopt for its unique business case.
A simple data quality framework or lifecycle consists of four stages:
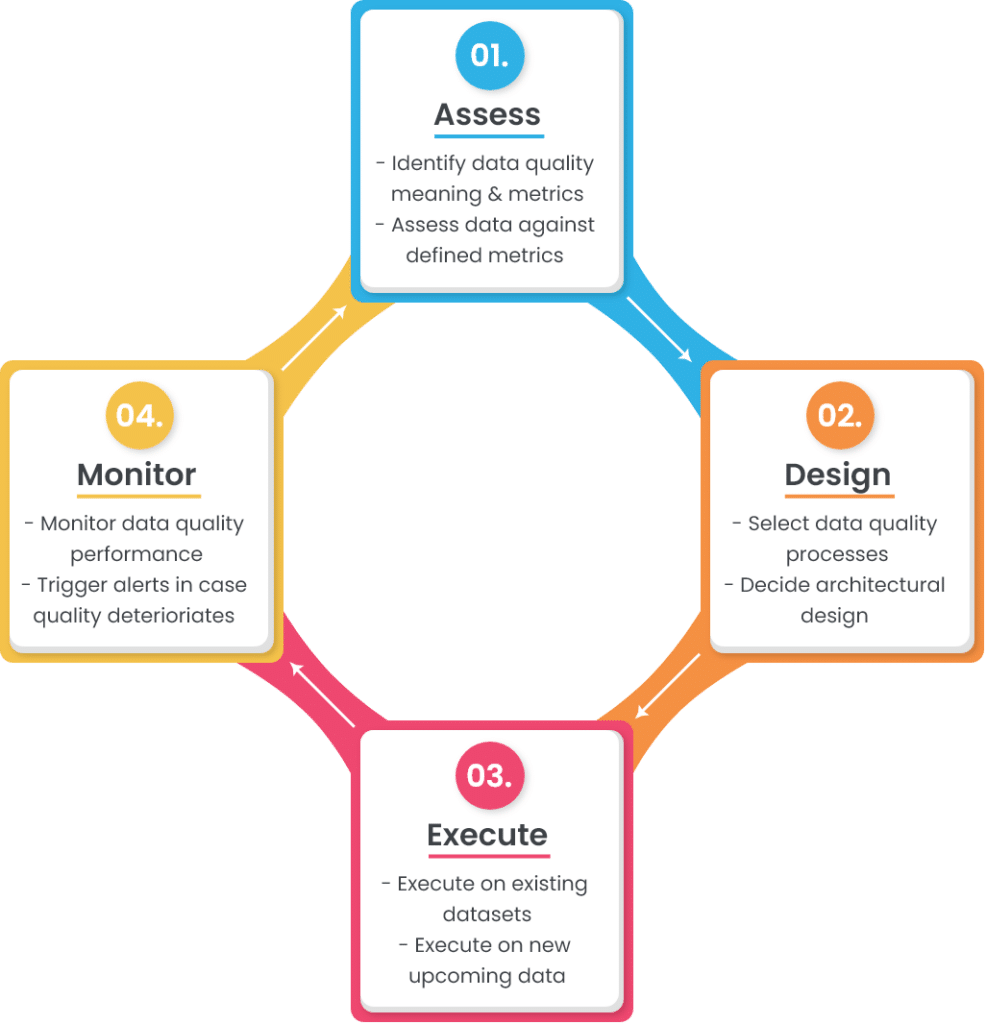
The upcoming sections discuss each of these stages in more detail.
1. Assess
This is the first step of the framework where you need to assess the two main components: the meaning of data quality for your business and how the current data scores against it.
a. Identify the meaning and metrics of data quality
Data quality is defined as the degree to which the data fulfills its intended purpose. And to define what data quality means for your business, you need to know the role it plays in different operations.
Let’s take a customer dataset as an example. An acceptable level of quality is required in your customer datasets – whether it is used to contact customers or analyzed for business decision-making. To define the meaning of good quality customer data, you have to do the following:
- Identify the sources where customer data comes from (web forms, third-party vendors, customers, etc.),
- Select the necessary attributes that complete customer information (name, phone number, email address, geographical address, etc.),
- Define metadata of selected attributes (data type, size, format, pattern, etc.)
- Explain the acceptability criteria for the data stored (name of customer needs to be 100% accurate at all times, while their product preferences can be up to 95% accurate).
This information is usually defined by drawing data models that highlight the necessary parts of data (the amount and quality of data that is considered good enough). Consider the following image to understand what a data model for a retail company can look like:
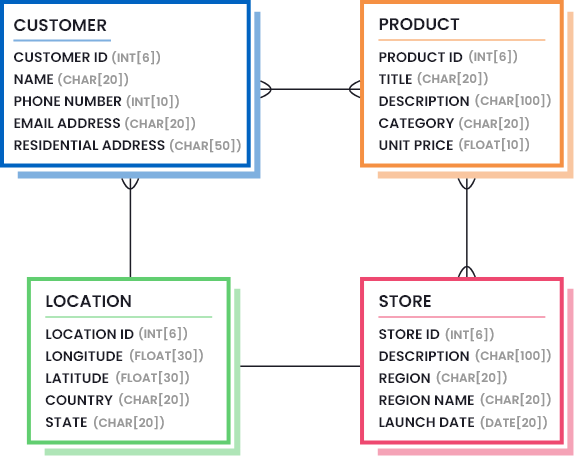
Furthermore, you need to identify the data quality metrics and their acceptable thresholds. A list of most common data quality metrics is given below, but you need to select the ones that are helpful in your case, and figure out the least percentile values that represent good data quality.
- Accuracy: How well do data values depict reality/correctness?
- Lineage: How trustworthy is the originating source of data values?
- Semantic: Are data values true to their meaning?
- Structure: Do data values exist in the correct pattern and/or format?
- Completeness: Is your data as comprehensive as you need it to be?
- Consistency: Do disparate data stores have the same data values for the same records?
- Currency: Is your data acceptably up to date?
- Timeliness: How quickly is the requested data made available?
- Reasonableness: Do data values have the correct data type and size?
- Identifiability: Does every record represent a unique identity and is not a duplicate?
b. Assess current datasets against defined metrics
The first step in assessment helps you to define the targets. The next step in assessment is to measure how well your current data performs against the set targets. This step is usually performed by generating detailed data profile reports. Data profiling is a process that analyzes the structure and contents of your datasets and uncovers hidden details.
Once data profile reports are generated, you can now compare them against the set target. For example, a set target could be that customers must have a first and last name; if the generated data profile report shows 85% completeness on customer name, you need to fetch the remaining 15% of the missing information.
2. Design
The next step in data quality framework is to design the business rules that will ensure conformance with the data model and targets defined in the assessment stage. The design stage consists of two main components:
- Selecting the data quality processes you need and finetuning them according to your needs,
- Deciding where to embed data quality functions (architectural design).
Let’s look at these in more detail.
a. Select data quality processes
Depending on the state of your data, you need to select a list of data quality processes that will help you to achieve the desired quality state. Usually, a number of data quality processes are performed to fix errors or transform data into the required shape and structure.
Below, we have listed the most common data quality processes used by organizations. The order in which they should be implemented on upcoming or existing data is your choice. The examples provided for each process will help you to navigate whether this process is useful for your case or it can be skipped.
i. Data parsing and merging
Data parsing means analyzing long strings and dividing sub-components into one or more columns. This is usually done to get important elements in separate columns so that they can be:
- Validated against a library of accurate values,
- Transformed into acceptable formats, or
- Matched with other records to find possible duplicates.
Similarly, sub-components are merged together to get more meaning out of individual fields.
Example: Parsing Address column into Street Number, Street Name, City, State, Zip Code, Country, etc.
ii. Data cleansing and standardization
Data cleansing and standardization is the process of eliminating incorrect and invalid information present in a dataset to achieve a consistent and usable view across all data sources.
Example:
- Removing null values, leading/trailing spaces, special characters, etc.,
- Replacing abbreviations with full forms, or repetitive words with standardized words,
- Transforming letter cases (lower to upper, upper to lower),
- Standardizing values so that they follow the correct pattern and format, and so on.
iii. Data matching and deduplication
Data matching (also known as record linkage and entity resolution) is the process of comparing two or more records and identifying whether they belong to the same entity. If multiple records are found to be a match, the main record is retained and the duplicates are removed to attain the golden record.
Example: If customer information at your company is captured and maintained at different sources (CRM, accounting software, email marketing tool, website activity tracker, etc.), you will soon end up with multiple records of the same customer. In such cases, you will need to perform exact or fuzzy matching to determine the records belonging to the same customer, and the ones that are possible duplicates.
How best-in class fuzzy matching solutions work
Read this whitepaper to explore the challenges of matching, how different types of matching algorithms, how a best-in-class software uses these algorithms to achieve data matching goals.
Download
iv. Data merge and survivorship
Once you find duplicate records in your dataset, you can simply delete the duplicates or merge them together to retain maximum information and prevent data loss. Data merge and survivorship is a data quality process that helps you to build rules that merge duplicate records together through conditional selection and overwriting.
Example: You may want to keep the record that has the longest Customer Name and use it as the master record, while overwriting the longest Zip Code from the duplicate record onto the master one. A prioritized list of such rules will help you to get the most out of your dataset.
v. Custom validation or dependency rules
Apart from the standardized data quality processes, you may have custom validation rules that are unique to your business operation.
Example: If a customer has made a Purchase of Product A, they can only avail a Discount of up to 20%. (Meaning: If Purchase = Product A, then Discount should be <= 20%).
Such business-specific dependency rules must be validated to ensure high data quality.
b. Decide architectural design
Now that we have taken a look at some common data quality processes used in a data quality framework, it’s time to consider a more important aspect: how are these data quality operations embedded in your data lifecycle?
There are multiple ways that this is possible, including:
1. Implementing data quality functions at input – this can involve putting validation checks on web forms or application interfaces used to store data.
2. Introducing middleware that validates and transforms incoming data before storing it in the destination source.

3. Putting validation checks on database, so that errors are raised while storing data in the data store.
Although the first way seems best, it has its own limitations. Since an average organization uses 40+ applications, it is difficult to synchronize each input source to produce the required output.
To know more, check out: How are data quality features packaged in software tools?
3. Execute
The third stage of the cycle is where the execution happens. You have prepared the stage in the previous two steps, now it’s time to see how well the system actually performs.
It is important to note that you may need to execute the configured processes on the existing data first and ensure its high quality. In the next phase, you can trigger execution on new upcoming streams of data.
4. Monitor
This is the last stage of the framework where the results are monitored. You can use the same data profiling techniques that were used during the assessment stage to generate detailed performance reports. The goal is to see how well the data conforms to the set targets, for example:
- Incoming data is parsed and merged as needed,
- The required attributes are not null,
- Abbreviated words are transformed as needed,
- Data is standardized according to the set format and pattern,
- Possible duplicates are merged together or deduplicated,
- Possible duplicates are not created as new records,
- Custom business rules are not being violated, etc.
Moreover, you can also set some thresholds for data quality measurement, and trigger alerts in case data quality deteriorates even a bit below these levels.
10 things to check when profiling your data
Data profiling is a crucial part of data conversion, migration and data quality projects. Download this whitepaper and find out the ten things to check when profiling your data.
Download
And here we go again…
A data quality cycle or framework is an iterative process. Once you’ve reached the monitoring stage, a few data quality errors might arise. This shows that the defined framework still has some gaps that caused errors to fall through. For this reason, the assessment stage must be triggered again, which consequently triggers the design and execution phases. In this way, your data quality framework is constantly upgraded and perfected to meet your data quality needs.
When is the cycle iterated?
There are two ways to trigger the assessment stage:
1. Proactive approach
In this approach, you can select a regular date and time when the generated performance reports are analyzed and in case any errors are encountered within that timeframe, the assessment stage is triggered again. This approach helps you to keep an eye out on possible errors that may arise.
2. Reactive approach
As the name suggests, the assessment stage is triggered when a data quality error is encountered. Although both approaches have their own benefits, it is best to apply both to your data quality framework so that the state of data quality is constantly proactively monitored as well as taken care of at the time any errors occur.
Conclusion
Data quality is not a one-stop destination. It is something that constantly needs to be assessed and improved. For this reason, it is very crucial to design comprehensive frameworks that continuously manage the quality of multiple datasets. Utilizing standalone data quality tools can be very productive for this case – given that they have the ability to:
- Integrate in the middle of your input and output sources,
- Perform detailed analysis to generate data profile reports,
- Support various data quality processes that can be finetuned and customized as needed,
- Offer batch processing or real-time processing services, and so on.
DataMatch Enterprise is one such solution – available as a standalone application as well as an integrable API – that enables end-to-end data quality management, including data profiling, cleansing, matching, deduplication, and merge purge.
You can download the free trial today, or schedule a personalized session with our experts to understand how we can help you to design a data quality framework for your business.
Getting Started with DataMatch Enterprise
Download this guide to find out the vast library of features that DME offers and how you can achieve optimal results and get the most out of your data with DataMatch Enterprise.
Download





