Measuring software quality
The word “quality” first appeared in the English language around 1300. Technically, “quality” is a neutral term, referring to the character or nature — good, bad, or otherwise — of a person, place, or thing. However, when we use this word today, we’re often implicitly pointing to high quality. Most modern definitions of “quality” indicate that the term is connected to attributes like lack of risk, ease of trust, superiority to competition, and high value.
When it comes to software, that last attribute — user value — is arguably the most important. As designers, engineers, and product managers, our goal is to deliver high-value products to clients and end users; to know whether we’ve succeeded, we need a consistent and accurate way to measure the quality of our work. The things we choose to measure will color our perception of the software we create, and will either reinforce or undermine our underlying objectives.
There are an almost limitless number of metrics that could give us insight into software quality, and each has a particular scenario in which it’s best used and a type of information it’s intended to provide. I’ll touch on some common metrics below, and then share some thoughts on the importance of testing and context when measuring quality.
Mục lục
Product quality metrics
There are two categories of metrics that we often use to measure the quality of a software product: intrinsic metrics and customer value metrics.
Intrinsic quality metrics give us an understanding of the state and stability of code. Two of the most common intrinsic quality metrics are mean time between failures, and defect density.
- Mean time between failures is a stability metric that has been used by hardware teams for decades, and is now also used by some less mature or less process-oriented software teams. The longer the time between significant failures (as defined by the product team), the higher the quality of the product. As failures grow further apart, the product is considered to be healthier and potentially closer to ready for launch.
- Defect density is a measure of the “bugginess” of code. It is calculated by dividing the number of confirmed defects in a period of operation, or when performing a specific function, by the number of lines of code executed.
Customer impact metrics consider the actual impact of failures, defects, and other product issues on the end user. Common customer impact metrics include usability (how intuitive is the product, and how quickly can a new user come up to speed on its functions?) and customer satisfaction. Satisfaction is especially difficult to measure, as it requires collecting and analyzing subjective data from a larger number of customers — but for teams that do it well, it is a gold standard metric that can highlight opportunities to significantly improve product quality.
Software quality metrics
Software quality metrics focus on the overall health of the software development process. While they are closely related to product quality, these metrics focus more on potential issues with testing, bug management, and code iteration. If product quality is low, software quality metrics may provide more insight into why.
Common software quality metrics include:
- Defect escape rate: A count of the number of bugs in production that “could” have been caught and fixed prior to release. Despite being one of the most commonly used and discussed software quality metrics, defect escape rate is actually fairly meaningless, because it assumes perfect knowledge of the number of bugs in production — something that very few, if any, software teams actually have.
- Code churn: A measure of the frequency with which a specific area of code has been deleted and rewritten or rearchitected. Code churn can help teams identify areas or problems that have been shoddily “patched”, and that require a step back and a more holistic approach to developing a robust solution.
- Test coverage (code coverage, requirements coverage): A measure of the percentage of code that is exercised in testing (or, in the case of requirements coverage, the percentage of functional requirements that are covered by tests). A high test coverage lends confidence that the code is being exercised properly and the tests will identify issues that should block release.
- QA defect density: Similar to defect density (see above), QA defect density measures the occurrence of bugs — but rather than calculating density relative to the total number of lines of code, we calculate it relative to new features or releases. This approach can help the team determine which areas are most problematic, and can point to processes or systems that should be revised for future releases.
- Bugs opened vs. closed (bug burn down rate): This metric provides great insight into the overall health of a software project, as it tells the team in two numbers (or one ratio) whether the project is moving forward or backward overall. The “bug burn down rate” is a visual representation of the open vs. closed ratio, and predicts the time at which (in theory) all bugs will be eliminated.
- Percentage of high priority bugs: Healthy products show a low percentage of high-priority bugs — with one major caveat, which is that the usefulness of this metric depends on the structure and consistency of the prioritization system. For example, some systems conflate priority and severity, which can lead to a higher (or lower) number of priority bugs that would be expected given the overall health of the product.
- Bug reopen rate: One of my personal favorite metrics. Bug reopen rate is similar in many ways to the open vs. closed ratio, but provides more direct insight into whether the team is making real progress or simply addressing the same bugs over and over again. A baseline reopen rate can also be used to forecast the amount of testing and iteration that will be needed in future releases.
- Test cases <status> percentages: The percentage of tests that pass, fail, are blocked, etc. in the current build. A good way to assess the status of a build, identify areas that need work as well as those that are performing well, and highlight areas that can’t yet be tested or where more tests are needed.
Why is testing so important?
You’ll notice that many of the software quality metrics above are in some way related to testing. I’m often asked why we do so much testing, and whether it’s really necessary. My response usually hits on two main points:
- Poor quality software is expensive. In 2018, the Consortium for IT Software Quality Assurance estimated the cost of poor quality software in the United States at more than $2.8 trillion per year. Additionally, according to one 2016 survey, 88 percent of Americans form a negative overall opinion of the brand when they encounter a poorly performing website or mobile app.
- Inadequate testing can and does result in catastrophic failure and the destruction of invaluable lives and property. We’ve seen stories about this in the news for decades — the Therac-25 disaster in the late 1980s, the Mars Climate Orbiter in 1998, the self-driving Uber tragedy in 2018, and many more.
Testing isn’t always exciting, but it matters, and we can’t build quality software without it.
Putting quality into context
Any of the metrics above is a good start toward measuring software quality — but metrics in isolation actually aren’t worth much. To really evaluate quality, we need to understand the context in which we’re measuring. Context-setting questions might include:
- What are the goals of the project?
- Which functions are most critical?
- Is this a large, mature, public-facing application, an MVP internal tool, or something in between?
- Are there software development lifecycle factors that might be influencing the quality metrics, such as the stability of requirements or how bugs are prioritized?
- How are our quality metrics trending over time, especially as the product evolves and matures? Are the trends steady, or are there big fluctuations and outliers that we need to look at more closely?
Here’s an example to illustrate the importance of context. We have two products — Product 1 is a mature, public-facing application that is receiving continual feedback from end users, while Product 2 is in an MVP phase heading toward its first public launch. The following graph shows the trend in bugs opened (in red) and closed (in green) for each product:
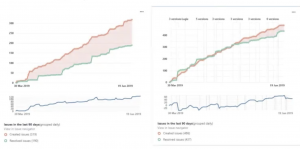
Both of these products are healthy. Product 1 has a higher relative number of opened bugs because it’s going through iterative discovery weekly as part of the process of reaching an effective MVP; but Product 2 has a higher total number of opened bugs because it has been in production for several years. Although the absolute numbers for these two products are very different, they are both appropriate for the stage of the product’s lifecycle.
So — which metrics matter, and what should they look like? There’s no one right answer; it depends on the product, the context, and the team. At the end of the day, though, software quality is about minimal confusion and maximum efficiency for end users and your team. If you’re minimizing this metric, you’re probably doing something right: